Cuda基础知识
Cuda编程模型
2006年,著名显卡厂商NVIDIA发布了CUDA(Compute Unified Device Architecture),是建立在NVIDIA的GPUs上的一个并行计算平台和编程模型。 在CUDA编程模型中,GPU被看作是一个协处理器,用于执行大量并行的线程运行。
程序员用类C语言编程,程序分为两部分:host端和device端。Host端是在CPU上执行的部分,而device端是在GPU上执行的部分。CUDA会把程序编译成GPU可以执行的程序,并且把数据从host端送入device端作并行处理,再把得到的多个结果从device端送回host端。
线程块的存储方式
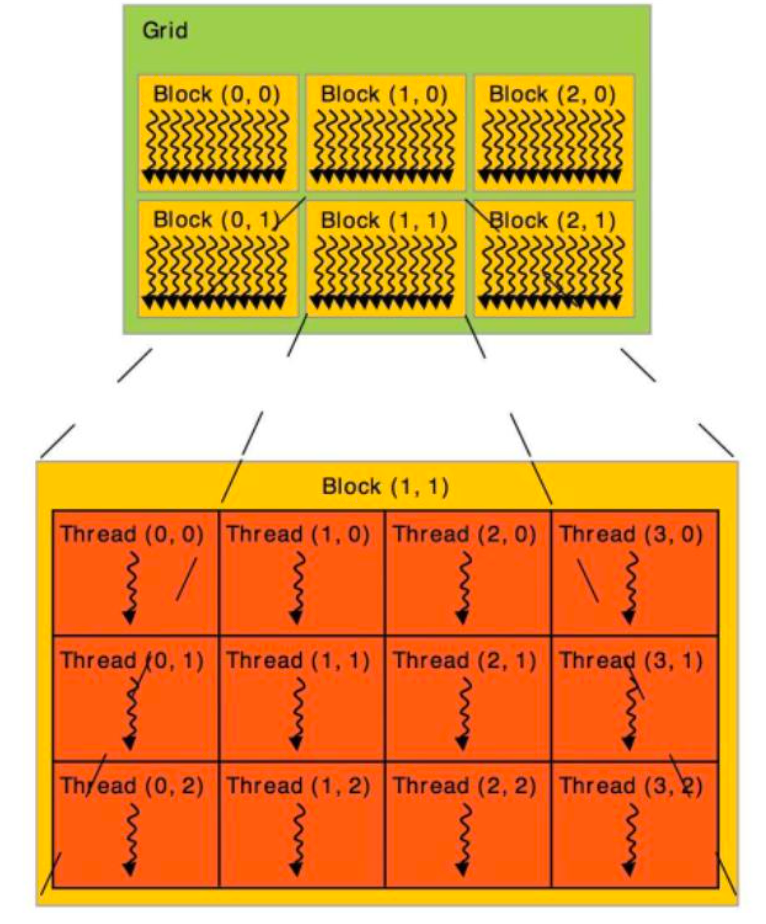
线程块的存储方式,涉及到3个层次,第一层网格(grid),第二层线程块(block),第三层线程(thread),它们的存储都可以想成是有长宽高的长方体。
如图展示的是线程和线程块均按二维排列的情况,blockDim, blockindx,threadIndx是常用的内置三维矢量索引。blockDim的三维分别是块的长宽高,blockIndx是在在网格内的索引,第一维blockIdx.x,指定线程在网格横向的第几个块,值为0到gridDim.x - 1之间;threadIdx是在块内的索引,第一维threadIdx.x:指定了线程在第几个块(block)中的第几个线程,值在0到blockDim.x - 1之间。

例如图中每个块中包含4列3行线程,因此blockDim.x大小为4,blockDim.y大小为3。图中Thread(i,j)的线程索引计算方式为i=blockIdx.x * blockDim.x+threadIdx.x;j=blockIdx.y * blockDim.y + threadIdx.y。
核函数
带__global声明的函数就是在 GPU 上运行的函数, 称之为核函数, 英文名 Kernel Function,一个 kernel 核函数所启动的所有线程称为一个网格 grid, 同一个网格上的线程共享相同的全局内存空间。假设你有 32 个数据元素用于计算,每个元素 1 个线程,每个 block 只用 8个线程,那就要启动 4 个 block,语法就是 kernel_name <<4, 8>>(arg list);
线程块
每个线程块是一个 block,它包含一批可以高速共享内存的线程,目前每个线程块所包含的最大线程数目是 512。同一个块中的线程之间可以相互协作,不同块内的线程不能协作。同块之间的线程是并行的,不同块不是并行的。
cuda的代码流程
取得一块显卡内存
1
cudaMalloc((void**)&cuda_a, sizeof(float)* size);
把 CPU 的数据放入 GPU 内
1
cudaMemcpy(cuda_a, a, sizeof(float)* size, cudaMemcpyHostToDevice);
设定内核函数 函数名称<<
>>(函数需要传入的参数) 如 1
sumOfSquares <<< BLOCK_NUM, THREAD_NUM, THREAD_NUM * sizeof(int) >>> (GPUdata, result, time);
把 GPU 的数据传出复制到 CPU 的变量里
1
cudaMemcpy(out, cuda_a, sizeof(float)* size, cudaMemcpyDeviceToHost);
释放用 cuda 取得的显卡内存
1
cudaFree(cuda_a);
